Part Distribution
This example focuses on a specific scheduling problem in manufacturing. Components need to be distributed across multiple parallel processes by a single switch (SwitchD) in an optimal manner. Additionally, another switch (SwitchF) is responsible for collecting the outputs from these processes and sending them to a final destination. These parallel processes differ in terms of the processing times. As a result, they need a different number of parts distributed by the switch in order to work optimally.
Within a given timeframe, the maximum number of parts that a process can produce is determined by ensuring a continuous supply of components without any interruptions. If the processing times of the source and the final destination are negligible compared to those of the processes, the total number of parts produced by the system is simply the sum of the parts produced by each individual process. This provides an estimate of the maximum production capacity of the system.
What is optimized?
We optimize the distribution of the parts by the switch (SwitchD) to the stations, considering the processing times of all processing stations. In addition, collecting the parts that have been processed and can now be pushed to the final station at the end of the line needs to be optimized (SwitchF). A policy implemented at both switches, that assigns components by placing them in the least filled buffer, while prioritizing faster processes, and retrieving them from the most filled buffer seems like the best approach for this problem. We examine the case with k=5 stations. Processing times vary with ∑ik 10+10*i + exp(0.2). The reward can be maximized by optimizing the part distribution of both switches.
Optimization using Lineflow
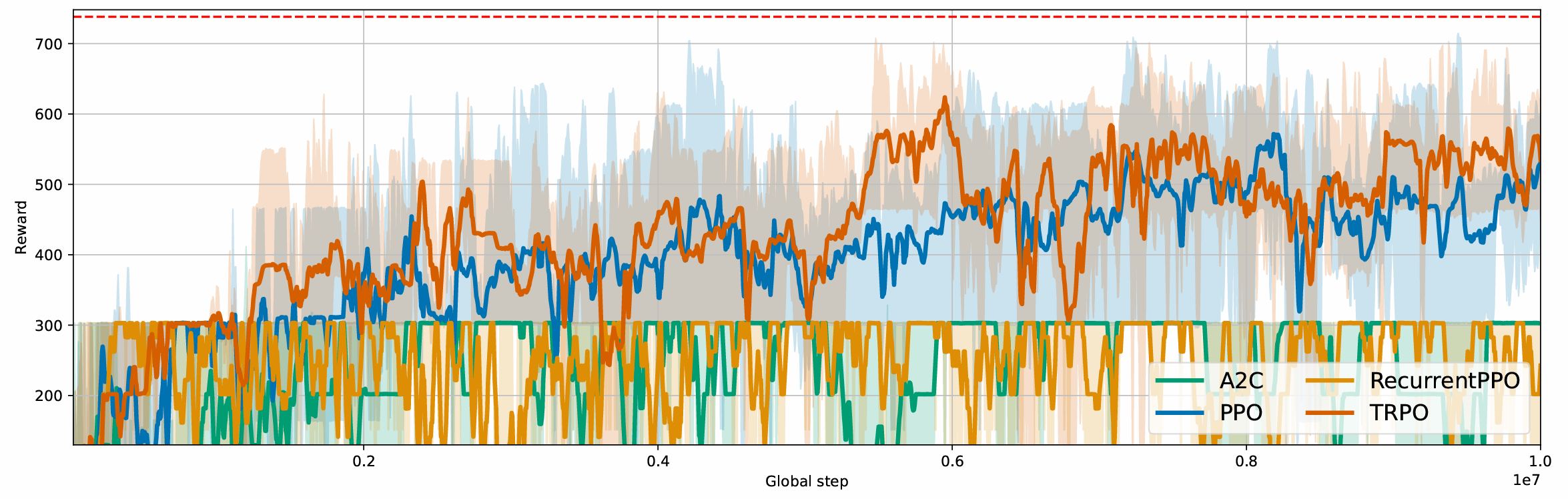
We validated the effectiveness of Lineflow algorithms by comparing them to the rewards
achieved by the greedy approach. Our optimal agent achieved rewards up to 738, as shown
in the plot below. Only the policy based methods PPO and TRPO ensure a proper switch distribution.
Verification of the optimization
As mentioned above, a greedy scheduling policy is implemented at both switches. This policy
prioritizes sending components to the least filled buffer and retrieving
components from the most filled buffer, ensuring an optimal distribution and therefore the
maximum number of parts produced.
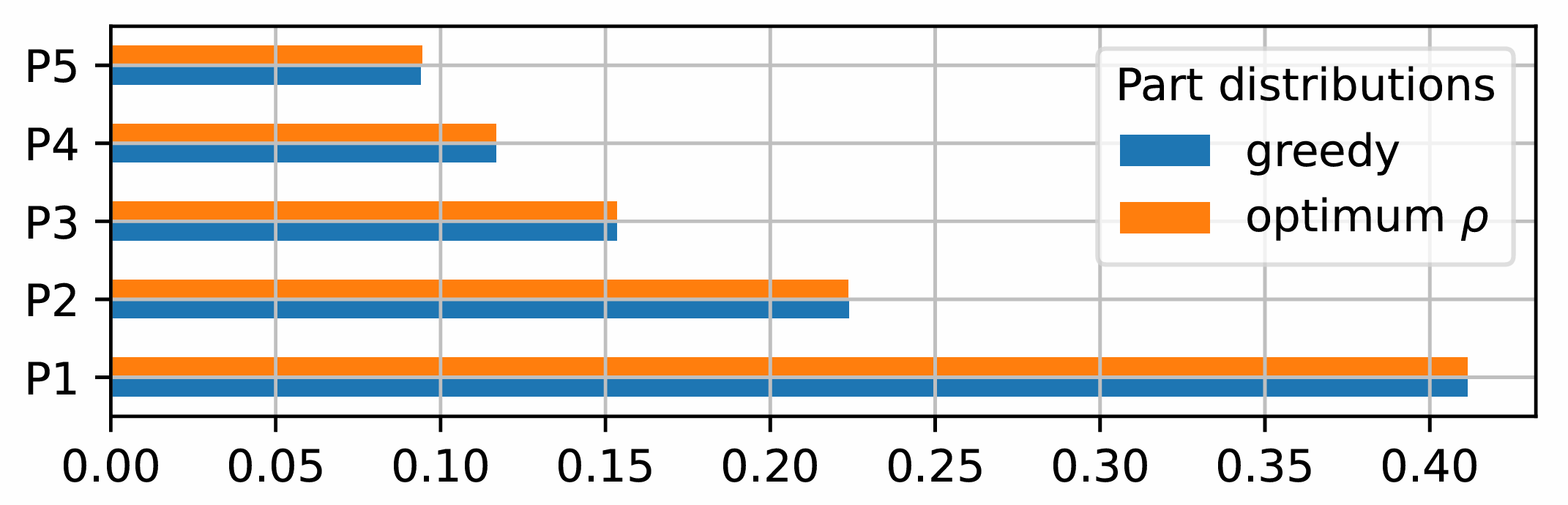
A comparison of the component distributions between the greedy policy and the optimal
distribution for 5 parallel processing cells is given in the following figure.
For a detailed calculation and proof of the optimal part distribution, see (Link to Lineflow paper).
Code
import numpy as np
from lineflow.simulation import (
Line,
Sink,
Source,
Switch,
Process,
)
def make_fast_only_policy(n_processes):
def policy(state, env):
return {
'SwitchF': {'index_buffer_in': 0, 'index_buffer_out': 0},
'SwitchD': {'index_buffer_in': 0, 'index_buffer_out': 0},
}
return policy
def make_greedy_policy(n_processes):
def policy(state, env):
# Fetch from buffer where fill is largest
fills_prior_process = np.array(
[state[f'Buffer_SwitchD_to_P{i}']['fill'].value for i in range(n_processes)]
)
fills_after_process = np.array(
[state[f'Buffer_P{i}_to_SwitchF']['fill'].value for i in range(n_processes)]
)
return {
# Fetch where fill is maximal
'SwitchF': {
'index_buffer_in': fills_after_process.argmax(),
},
# Push where fill is minimal
'SwitchD': {
'index_buffer_out': fills_prior_process.argmin()
},
}
return policy
class MultiProcess(Line):
"""
Assembly line with two sources a switch and a sink
"""
def __init__(self, alternate=True, n_processes=5, **kwargs):
self.alternate = alternate
self.n_processes = n_processes
super().__init__(**kwargs)
def build(self):
source = Source(
name='Source',
processing_time=2,
actionable_magazin=False,
actionable_waiting_time=False,
unlimited_carriers=True,
carrier_capacity=1,
position=(50, 300),
processing_std=0,
)
switch_d = Switch(
'SwitchD',
position=(200, 300),
alternate=self.alternate,
processing_time=1,
)
switch_f = Switch(
'SwitchF',
position=(900, 300),
alternate=self.alternate,
processing_time=1,
)
processes = []
for i in range(self.n_processes):
processes.append(
Process(
name=f'P{i}',
processing_time=12+10*i,
position=(600, 500-100*i),
processing_std=0.1,
)
)
sink = Sink('Sink', position=(1100, 300), processing_time=1, processing_std=0)
switch_f.connect_to_output(sink, capacity=2, transition_time=5)
switch_d.connect_to_input(source, capacity=2, transition_time=5)
for process in processes:
process.connect_to_input(switch_d, capacity=8, transition_time=7)
process.connect_to_output(switch_f, capacity=5, transition_time=7)
if __name__ == "__main__":
n_processes = 10
line = MultiProcess(n_processes=n_processes, realtime=True, factor=0.1, alternate=False)
agent = make_greedy_policy(n_processes)
line.run(simulation_end=3000, agent=agent, visualize=True)
print('Number of parts produced: ', line.get_n_parts_produced())